Analyse en Composantes Principales (ACP)
L'Analyse en Composantes Principales (ACP) est l'une des méthodes de data mining les plus populaires. Elle est disponible dans Excel avec le logiciel XLSTAT.

Qu'est-ce que l'analyse en composantes principales ?
Définition d'une analyse en composantes principales
L'analyse en composantes principales est l'une des méthodes d'analyse de données multivariées les plus fréquemment utilisées. Elle permet d'étudier des ensembles de données multidimensionnelles avec des variables quantitatives. Elle est largement utilisée en biostatistique, en marketing, en sociologie et dans de nombreux autres domaines.
Il s'agit d'une méthode de projection car elle projette les observations d'un espace à p dimensions avec p variables vers un espace à k dimensions (où k < p) de manière à conserver le maximum d'information (l'information est mesurée ici par la variance totale de l'ensemble de données) des dimensions initiales. Les dimensions de l'ACP sont également appelées axes ou facteurs. Si l'information associée aux 2 ou 3 premiers axes représente un pourcentage suffisant de la variabilité totale du nuage de points, les observations peuvent être représentées sur un graphique à 2 ou 3 dimensions, ce qui facilite grandement l'interprétation.
L'ACP peut donc être considérée comme une méthode d'exploration de données car elle permet d'extraire facilement des informations de grands ensembles de données. Elle peut être utilisée à plusieurs fins, notamment :
- L'étude et la visualisation des corrélations entre les variables, afin d'éventuellement limiter le nombre de variables à mesurer par la suite ;
- L'obtention de facteurs non corrélés qui sont des combinaisons linéaires des variables de départ, afin d'utiliser ces facteurs dans des méthodes de modélisation telles que la régression linéaire, la régression logistique ou l'analyse discriminante ;
- La visualisation des observations dans un espace à deux ou trois dimensions, afin d'identifier des groupes homogènes d'observations, ou au contraire des observations atypiques.
XLSTAT propose une fonction PCA complète et flexible pour explorer vos données directement dans Excel. XLSTAT propose plusieurs options standards et avancées qui vous permettront d'obtenir une vision approfondie de vos données.
Comment configurer une Analyse en Composantes Principales dans XLSTAT ?
ACP sur Pearson ou Covariance
L'ACP permet de calculer des matrices pour projeter les variables dans un nouvel espace en utilisant une nouvelle matrice qui montre le degré de similarité entre les variables. Il est courant d'utiliser le coefficient de corrélation de Pearson ou la covariance comme indice de similarité. La corrélation et la covariance de Pearson ont l'avantage de donner des matrices positives semi-définies dont les propriétés sont utilisées dans l'ACP. Cependant d'autres indices peuvent être utilisés.
XLSTAT propose plusieurs traitements de données qui peuvent être utilisés sur les données d'entrée avant les calculs d'Analyse en Composantes Principales :
- Pearson, l'ACP classique, qui standardise ou normalise automatiquement les données avant les calculs pour éviter de gonfler l'impact des variables à forte variance sur le résultat.
- Covariance, qui travaille sur les variances et les covariances non normalisées (les variables à variances élevées joueront un rôle plus important dans les résultats).
- Spearman, totalement équivalent à une ACP classique (basé sur la corrélation de Pearson) réalisé sur la matrice des rangs.
Traditionnellement, on utilise un coefficient de corrélation plutôt que la covariance car l'utilisation d'un coefficient de corrélation supprime l'effet d'échelle : ainsi une variable qui varie entre 0 et 1 ne pèse pas plus dans la projection qu'une variable variant entre 0 et 1000. Cependant, dans certains domaines, lorsque les variables sont censées être sur une échelle identique ou que l'on veut que la variance des variables influence la construction des facteurs, on utilise la covariance.
Lorsque l'on ne dispose que d'une matrice de similarité plutôt que d'un tableau d'observations/variables, ou lorsque l'on souhaite utiliser un autre indice de similarité, on peut effectuer une ACP à partir de la matrice de similarité (corrélation ou covariance).
ACP avec variables et observations supplémentaires
XLSTAT vous permet d'ajouter des variables (qualitatives ou quantitatives) ou des observations à l'ACP après qu'elle ait été calculée. Ces variables ou observations sont dites supplémentaires. Ceci peut être utilisé dans plusieurs contextes. Voici deux exemples :
- Si l'utilisateur veut étudier grossièrement la relation entre un ensemble de variables dépendantes et les autres. L'ensemble des variables dépendantes doit être utilisé ici comme un ensemble de variables supplémentaires et les autres (c'est-à-dire les variables indépendantes) doivent être utilisées pour construire l'ACP.
- Si l'utilisateur veut simplement voir comment différentes catégories d'observations se comportent dans l'espace de l'ACP (Hommes vs Femmes par exemple). Dans ce cas, une variable qualitative supplémentaire (sexe) peut être utilisée pour colorer les observations en fonction du sexe auquel elles appartiennent. Il est également possible d'afficher les centroïdes des catégories ainsi que les ellipses de confiance autour des catégories.
ACP avec rotations : Varimax et autres
Des rotations peuvent être appliquées sur les facteurs. Plusieurs méthodes sont disponibles dont Varimax, Quartimax, Equamax, Parsimax, Quartimin et Oblimin et Promax.
Quels sont les résultats de l'Analyse en Composantes Principales dans XLSTAT ?
L'ACP de XLSTAT fournit des résultats relatifs aux variables et aux observations.
Statistiques descriptives : le tableau de statistiques descriptives présente pour toutes les variables sélectionnées des statistiques simples. Sont affichés le nombre d'observations, le nombre de données manquantes, le nombre de données non manquantes, la moyenne, et l'écart-type (non biaisé).
Matrice de corrélation/de covariance : ce tableau correspond aux données qui sont ensuite utilisées pour les calculs. Le type de corrélation dépend de l'option qui a été choisie dans l'onglet « Général » de la boîte de dialogue. Dans le cas de corrélations, les corrélations significatives sont affichées en gras.
Test de sphéricité de Bartlett : les résultats du test de sphéricité de Bartlett sont affichés. Ils permettent de valider ou d'infirmer l'hypothèse selon laquelle les variables ne sont pas significativement corrélées.
Mesure de précision de l'échantillonnage de Kaiser-Meyer-Olkin : ce tableau donne pour chaque variable la valeur de la mesure KMO ainsi que le KMO global. L'indice KMO varie entre 0 et 1. Une valeur faible correspond au cas où il n'est pas possible d'extraire de facteurs synthétiques (ou variables latentes). Autrement dit, les individus ne permettent pas de faire ressortir le modèle que l'on pouvait imaginer préalablement (l'échantillon est « inadéquat »). Kaiser (1974) recommande de ne pas accepter une décomposition si le KMO est inférieur à 0.5. Si le KMO est entre 0.5 et 0.7 alors la qualité de l'échantillon est moyenne, elle est bonne pour un KMO entre 0.7 et 0.8, très bonne entre 0.8 et 0.9 et excellente au-delà.
Valeurs propres : les valeurs propres et le graphique (scree plot ) correspondant sont affichés. Le nombre de valeurs propres est égal au nombre de valeurs propres non nulles.
Si les options de sorties correspondantes ont été activées, XLSTAT affiche ensuite les coordonnées des variables dans le nouvel espace, puis les corrélations entre les variables d'origine et les composantes dans le nouvel espace. Les corrélations sont égales aux coordonnées des variables dans le cas d'une ACP normée (sur matrice de corrélation).
Si des variables supplémentaires ont été sélectionnées les coordonnées et les corrélations correspondantes sont affichées en fin de tableau.
Contributions : les contributions sont une aide à l'interprétation. Les variables ayant le plus influencé la construction des axes sont celles dont les contributions sont les plus élevées.
Cosinus carrés : comme pour les autres méthodes factorielles, l'analyse des cosinus carrés permet d'éviter des erreurs d'interprétation dues à des effets de projection. Si les cosinus carrés associés aux axes utilisés sur un graphique sont faibles, on évitera d'interpréter la position de l'observation ou de la variable en question.
Les coordonnées des observations dans le nouvel espace sont ensuite affichées. Si des données supplémentaires ont été sélectionnées, elles sont affichées en fin de tableau.
Contributions : ce tableau fournit les contributions des observations à la construction des composantes principales.
Cosinus carrés : dans ce tableau sont affichés les cosinus carrés entre les vecteurs observations et les axes factoriels.
Dans le cas où une rotation a été demandée, les résultats de la rotation sont affichés, avec en premier la matrice de rotation appliquée aux coordonnées des variables. Suivent ensuite les pourcentages modifiés de variabilité associés à chacun des axes concernés par la rotation. Dans les tableaux suivants sont affichées les coordonnées, les contributions et les cosinus des variables et des observations après rotation.
Quels graphiques sont affichés pour l'analyse en composantes principales dans XLSTAT ?
L'un des avantages de l'Analyse en Composantes Principales est qu'elle fournit à la fois une visualisation optimale des variables et des données, et des biplots mélangeant les deux (voir ci-dessous). Néanmoins, ces représentations ne sont fiables que si la somme des pourcentages de variabilité associés aux axes de l'espace de représentation, est suffisamment élevée. Si ce pourcentage est élevé (par exemple 80%), on peut considérer que la représentation est fiable. Si le pourcentage est faible, il est conseillé de faire des représentations sur plusieurs couples d'axes afin de valider l'interprétation faite sur les deux premiers axes factoriels.
Le cercle de corrélation de l'ACP
Le cercle de corrélation (ou graphique des variables) montre les corrélations entre les composantes et les variables initiales. Les variables supplémentaires peuvent également être affichées sous forme de vecteurs.
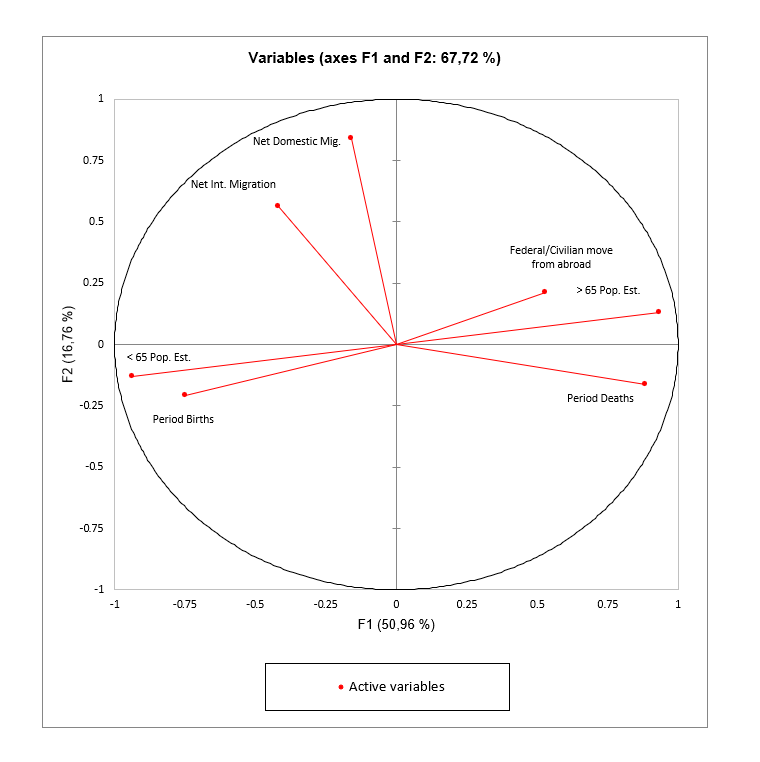
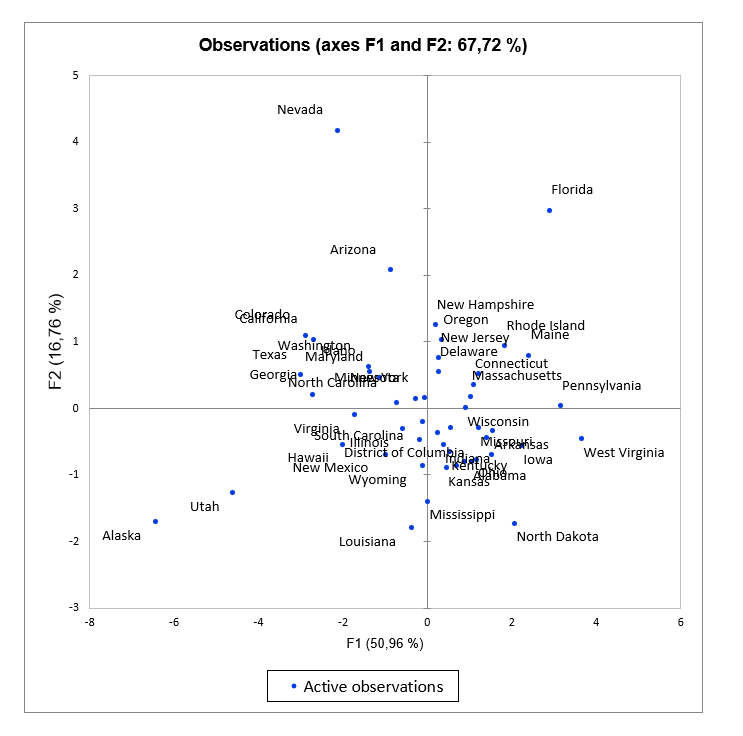
Les graphiques d'observations de l'ACP
Les graphiques d'observations représentent les observations dans l'espace ACP.
Les biplots de l'ACP
Suite à une Analyse en Composantes Principales, il est possible de représenter simultanément dans l'espace des facteurs à la fois les observations et les variables. Les premiers travaux sur ce sujet datent de Gabriel (1971). Gower (1996) et Legendre (1998) ont synthétisé les travaux précédents et étendu cette technique de représentation graphique à d'autres méthodes. Le terme biplot est réservé aux représentations simultanées qui respectent le fait que la projection des observations sur les vecteurs variables doit être représentative des données d'entrée pour ces mêmes variables. Autrement dit, les points projetés sur le vecteur variable, doivent respecter l'ordre et les distances relatives des données de départ correspondant à la même variable.
La représentation simultanée des observations et des variables ne peut être faite directement en prenant les coordonnées des variables et des observations dans l'espace des facteurs. Une transformation est nécessaire afin de rendre l'interprétation exacte. Trois méthodes sont proposées en fonction du type d'interprétation que l'on souhaite pouvoir faire à partir de la représentation graphique :
- biplot de corrélation (correlation biplot) : ce type de biplot permet d'interpréter les angles entre les variables car ils sont directement liés aux corrélations entre les variables. La position de deux observations projetées sur un vecteur variable permet de conclure quant à leur niveau relatif sur cette même variable. La distance entre deux observations est une approximation de la distance de Mahalanobis dans l'espace des k facteurs. Enfin, la projection d'un vecteur variable dans l'espace de représentation est une approximation de l'écart-type de la variable (la longueur du vecteur dans l'espace des k facteurs est égale à l'écart-type de la variable).
- biplot de distance (distance biplot) : un biplot de distance permet d'interpréter les distances entre les observations car elles sont une approximation de leur distance euclidienne dans l'espace des p variables. La position de deux observations projetées sur un vecteur variable permet de conclure quant à leur niveau relatif sur cette même variable. Enfin, la longueur d'un vecteur variable dans l'espace de représentation est représentative du niveau de contribution de la variable à la construction de cet espace (la longueur du vecteur est la racine carrée de la somme des contributions).
- biplot symétrique (symmetric biplot) : ce biplot proposé par Jobson (1992) est intermédiaire entre les deux biplots précédents. Si ni les angles ni les distances ne peuvent être interprétés, on peut choisir cette représentation car elle est un compromis entre les deux.
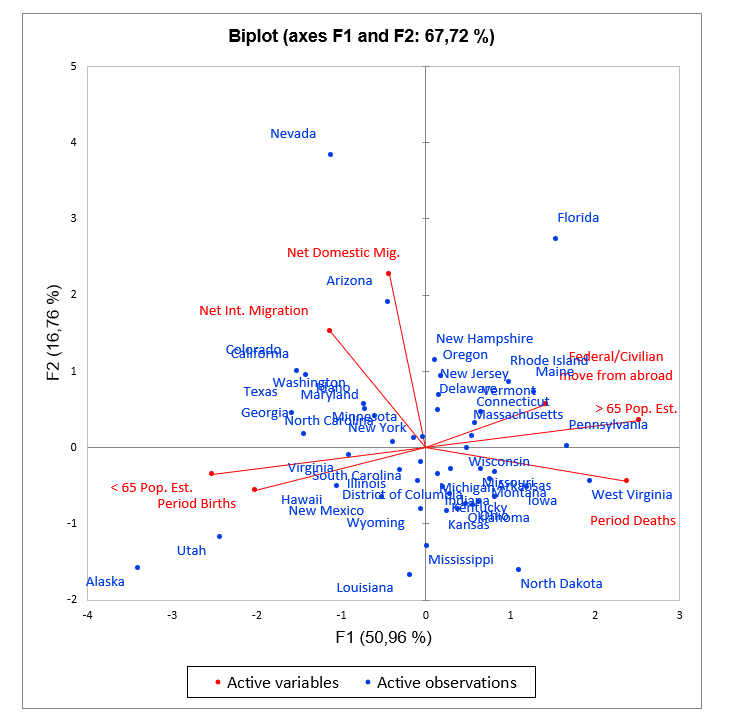
XLSTAT vous donne la possibilité de jouer sur la longueur des vecteurs variables afin d'améliorer la lisibilité des graphiques. Néanmoins, si vous utilisez cette option dans le cas d'un biplot de corrélation, la projection d'un vecteur variable n'est plus une approximation de l'écart-type de la variable.
Tutoriel ACP dans XLSTAT
Plusieurs exemples et applications sont disponibles sur notre site web et vous aideront à mettre en place et à interpréter une analyse PCA en fonction de vos besoins.
- Un exemple sur la façon d'exécuter une analyse en composantes principales (ACP).
- Un exemple sur la façon d'exécuter une analyse en composantes principales (ACP) avec des variables et des individus supplémentaires.
- Un exemple sur la façon de personnaliser un graphique d'analyse en composantes principales (ACP) pour une interprétation plus facile.
- Un exemple sur la façon d'utiliser l'analyse en composantes principales et d'appliquer des filtres sur les observations et les variables.


analysez vos données avec xlstat
Fonctionnalités corollaires