Sensitivity and specificity analysis
Sensitivity and specificity analysis allows evaluating the performance of a test. Available in Excel using the XLSTAT add-on statistical software.

Sensitivity and specificity analysis allows evaluating the performance of a test. Available in Excel using the XLSTAT add-on statistical software.
What is sensitivity and specificity analysis?
Sensitivity and Specificity analysis is used to assess the performance of a test. In medicine, it can be used to evaluate the efficiency of a test used to diagnose a disease or in quality control to detect the presence of a defect in a manufactured product.
The XLSTAT sensitivity and specificity feature allows computing, among others, the sensitivity, specificity, odds ratio, predictive values, and likelihood ratios associated with a test or a detection method.
When was this analysis developed?
This method was first developed during World War II to develop effective means of detecting Japanese aircraft. It was then applied more generally to signal detection and medicine, where it is now widely used.
Principles of Sensitivity and Specificity method
We study a phenomenon, often binary (for example, the presence or absence of a disease) and we want to develop a test to detect effectively the occurrence of a precise event (for example, the presence of the disease).
In XLSTAT, we can run many analyses such as k nearest neighbors, linear or cuadratic discriminant analysis, logistic regression, Lasso or Ridge…
Let V be the binary or multinomial variable that describes the phenomenon for N individuals that are being followed. We note by + the individuals for which the event occurs, and by - those for which it does not. Let T be a test which goal is to detect whether the event occurred or not. T can be a binary (presence/absence), a qualitative (for example the color), or a quantitative variable (for example a concentration). For binary or qualitative variables, let t1 be the category corresponding to the occurrence of the event of interest. For a quantitative variable, let t1 be the threshold value under or above which the event is assumed to happen.
Once the test has been applied to the N individuals, we obtain an individual/variable table in which for each individual you find whether the event occurred or not, and the result of the test.
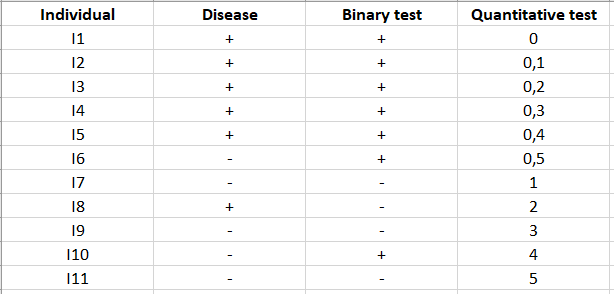
These tables can be summarized in a 2x2 contingency table:
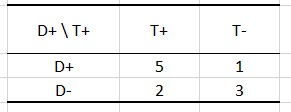
In the example above, there are 7 individuals for whom the test has detected the presence of the disease and 4 for which it has detected its absence. However, for 1 individual, diagnosis is bad because the test contends the absence of the disease while the patient is sick.
The following vocabulary is being used:
- True positive (TP): Number of cases that the test declares positive and that are truly positive. Here this value is 5.
- False positive (FP): Number of cases that the test declares positive and that in reality are negative. Here this value is 2.
- True negative (TN): Number of cases that the test declares negative and that are truly negative. Here this value is 3.
- False negative (FN): Number of cases that the test declares negative and that in reality are positive. Here this value is 1.
How to interpret the indices for Sensitivity and Specificity?
Several indices are available in XLSTAT software to evaluate the performance of a test:
- Sensitivity (equivalent to the True Positive Rate): Proportion of positive cases that are well detected by the test. In other words, the sensitivity measures how the test is effective when used on positive individuals. The test is perfect for positive individuals when sensitivity is 1, equivalent to a random draw when sensitivity is 0.5. If it is below 0.5, the test is counter-performing, and it would be useful to reverse the rule so that sensitivity is higher than 0.5 (provided that this does not affect the specificity). The mathematical definition is given by:
Sensitivity = TP/(TP + FN).
For example, here it is of 5/(5+1)=5/6.~0.83. It means that only 83% of the positive individuals have been predicted to be positive.
- Specificity (also called True Negative Rate): proportion of negative cases that are well detected by the test. In other words, specificity measures how the test is effective when used on negative individuals. The test is perfect for negative individuals when the specificity is 1, equivalent to a random draw when the specificity is 0.5. If it is below 0.5, the test is counter performing-and it would be useful to reverse the rule so that specificity is higher than 0.5 (provided that this does not impact the sensitivity). The mathematical definition is given by:
Specificity = TN/(TN + FP).
For example, here it is of 3/(3+2)=60%. It means that only 60% of the negative individuals have been predicted as negative.
- False Positive Rate (FPR): Proportion of negative cases that the test detects as positive.
FPR = 1-Specificity=FR/(TN+FP)
Here, it is of 1-60%=40%. It means that 40% of the negative individuals have been predicted as positive.
- False Negative Rate (FNR): Proportion of positive cases that the test detects as negative.
FNR = 1-Sensibility=FN/(TP+FN)
Here, it is of 1-5/6=1/6~0.17. It means that 17% of the positive individuals have been predicted as negative.
- Prevalence: relative frequency of the event of interest in the total sample (TP+FN)/N. Here, it is (6+1)/11=7/11~0.64. It means that in reality there are 64% of positive events in the sample.
More indices are also available, such as PPV and NPV.
How to interpret PPV and NPV?
- Positive Predictive Value (PPV): Proportion of truly positive cases among the positive cases detected by the test.
We have PPV = TP / (TP + FP), or PPV = Sensitivity x Prevalence / [(Sensitivity x Prevalence + (1-Specificity)(1-Prevalence)].
It is a fundamental value that depends on the prevalence, an index that is independent of the quality of the test.
Here, the PPV is of 5/(5+2)=5/7~0.71. It means that the true positives represent 71% of the values predicted as positive.
- Negative Predictive Value (NPV): Proportion of truly negative cases among the negative cases detected by the test.
We have NPV = TN / (TN + FN), or PPV = Specificity x (1 - Prevalence) / [(Specificity (1-Prevalence) + (1-Sensibility) x Prevalence].
This index also depends on the prevalence that is independent of the quality of the test.
Here, it is of 3/(3+1)=75%. It means that the true negatives represent 75% of the values predicted as negative.
Finally, some ratio and risk indices are available in XLSTAT.
- Positive Likelihood Ratio (LR+): This ratio indicates at which point an individual has more chances to be positive in reality when the test is telling it is positive.
We have LR+ = Sensitivity / (1-Specificity).
The LR+ is a positive or null value.
In our example, it is of (5/6)/(1-0.4)=(5/6)/(6/10)=25/18~1.4. It means that the chances of diagnosing a positive individual as positive are approximately 1.4 times greater than a negative one.
- Negative Likelihood Ratio (LR-): This ratio indicates at which point an individual has more chances to be negative in reality when the test is telling it is positive.
We have LR- = (1-Sensitivity) / (Specificity).
The LR- is a positive or null value.
Here, it is of (1/6)/(4/10)=5/12~0.42. It means that the chances of diagnosing a negative individual as negative only represent approximately 0.42 of when the individual is positive.
- Odds ratio: The odds ratio indicates how much an individual is more likely to be positive if the test is positive, compared to cases where the test is negative. For example, an odds ratio of 2 means that the chance that the positive event occurs is twice higher if the test is positive than if it is negative. The odds ratio is a positive or null value.
We have Odds ratio = TPxTN / (FPxFN).
Here, it is of (5x3)/(2x1)=15/2=7.5. It means that it’s 7.5 times more likely for the individual to be positive if the test is positive than when it’s negative.
- Relative risk: The relative risk is a ratio that measures how better the test behaves when it is a positive report than when it is negative. For example, a relative risk of 2 means that the test is twice more powerful when it is positive than when it is negative. A value close to 1 corresponds to a case of independence between the rows and columns, and to a test that performs as well when it is positive as when it is negative.
Relative risk is a null or positive value given by: relative risk = TP/(TP+FP) / (FN/(FN+TN)).
Here, it is of (5/7)/(1/4)=20/7~2.86. It means that the test is approximately 2.86 times better at detecting positive individuals than negative ones.
Confidence intervals for Sensitivity and Specificity analysis
For the various presented above, several methods of calculating their variance and, therefore their confidence intervals, have been proposed. There are two families: the first concerns proportions, such as sensitivity and specificity, and the second ratios, such as LR+, LR- the odds ratio and the relative risk.
For proportions, XLSTAT allows you to use the simple (Wald, 1939) or adjusted (Agresti and Coull, 1998) Wald intervals, a calculation based on the Wilson score (Wilson, 1927), possibly with a correction of continuity, or the Clopper-Pearson (1934) intervals. Agresti and Caffo recommend using the adjusted Wald interval or the Wilson score intervals.
For ratios, the variances are calculated using a single method, with or without correction for continuity.
Once the variance of the above statistics is calculated, we assume their asymptotic normality (or of their logarithm for ratios) to determine the corresponding confidence intervals. Many of the statistics are proportions and should lie between 0 and 1. If the intervals fall partly outside these limits, XLSTAT automatically corrects the bounds of the interval.
Do not hesitate to have a look at our tutorial on how to run a sensitivity and specificity analysis in XLSTAT.


analyze your data with xlstat
Related features