Feature extraction
This feature allows users to extract features vectors from a collection of text documents. Available in Excel using the XLSTAT statistical software.

What is feature extraction?
Feature extraction is a text mining method which aims to reduce the amount of resources required to describe a large set of textual data. It is a general term for methods of constructing combinations of the variables to get around these problems while still describing the data with sufficient accuracy.
The extracted features are commonly used in methods of document classification where the frequency of occurrence of each word in a document is used as a feature for training a classifier.
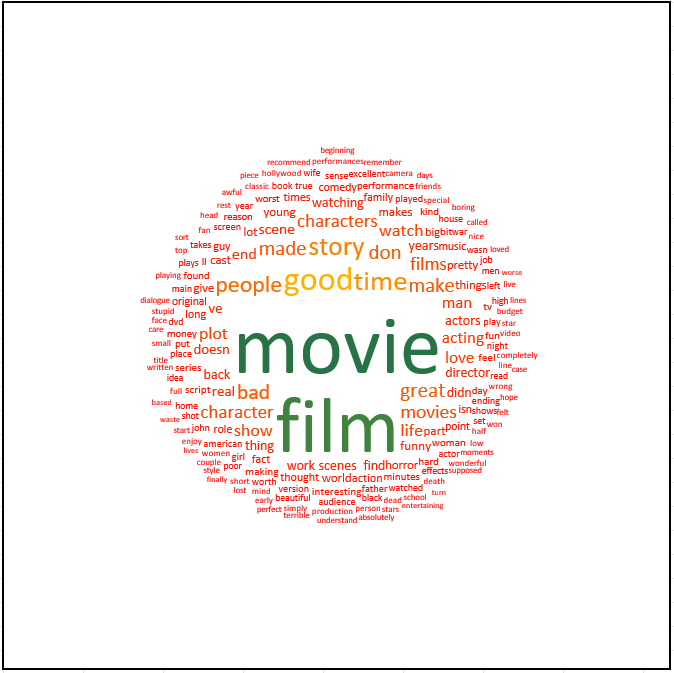
This feature is the first step in creating a word cloud. In XLSTAT, it can be done in a single step by checking the corresponding option.
Feature extraction model in XLSTAT
Bag-of-words representation
Also known as vector space model. In this model, a text (such as a sentence or a document) is represented as a multiset of its words, disregarding grammar and even word order. A classical output is the document-term matrix.
Feature extraction output in XLSTAT
Document-term matrix: it uses all the tokens in the dataset as vocabulary. It is a mathematical matrix object that describes the frequency of terms that occur in a collection of documents. In a document-term frequency matrix, each row in the matrix corresponds to a document and each column corresponds to a term (word) in the document. Each cell represents the frequency (number of occurrences) of the corresponding word in the corresponding document
Prior to that, a tokenization step is performed to separate words from the document by using white space as the delimiter. Moreover, many different filtering combinations can are applied as removing words that do not have any significant importance in building the matrix. This process is called stop words removal (stop words are words like a, the, that and so on). Others filtering procedures can be performed as removing sparse terms (terms that are not present above a certain proportion over the whole documents) or stemming to remove in flexional ending from the necessary words (thus reducing inflected words to their word stem).
Word cloud: Activate this option to display the word cloud representing all documents.


analyze your data with xlstat
Related features